8.7 Single web page
8.7.1 Read_html
## {html_document}
## <html>
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body>\n <div id="appTidyverseSite" class="shrinkHeader alwaysShrinkHead ...Because the downloaded file contains a unnecessary information. We process the data to extract only the text from the webpage.
8.7.2 Extract headline
header_web_page <- web_page %>%
## extract paragraphs
rvest::html_nodes("h1") %>%
## extract text
rvest::html_text()
head(header_web_page)## [1] "Tidyverse packages"8.7.3 Extract text
web_page_txt <- web_page %>%
## extract paragraphs
rvest::html_nodes("p") %>%
## extract text
rvest::html_text()
head(web_page_txt)## [1] "Install all the packages in the tidyverse by running install.packages(\"tidyverse\")."
## [2] "Run library(tidyverse) to load the core tidyverse and make it available\nin your current R session."
## [3] "Learn more about the tidyverse package at https://tidyverse.tidyverse.org."
## [4] "The core tidyverse includes the packages that you’re likely to use in everyday data analyses. As of tidyverse 1.3.0, the following packages are included in the core tidyverse:"
## [5] "ggplot2 is a system for declaratively creating graphics, based on The Grammar of Graphics. You provide the data, tell ggplot2 how to map variables to aesthetics, what graphical primitives to use, and it takes care of the details. Go to docs..."
## [6] "dplyr provides a grammar of data manipulation, providing a consistent set of verbs that solve the most common data manipulation challenges. Go to docs..."8.7.4 Create a corpus
## Corpus consisting of 31 documents.
## text1 :
## "Install all the packages in the tidyverse by running install..."
##
## text2 :
## "Run library(tidyverse) to load the core tidyverse and make i..."
##
## text3 :
## "Learn more about the tidyverse package at https://tidyverse...."
##
## text4 :
## "The core tidyverse includes the packages that you’re likely ..."
##
## text5 :
## "ggplot2 is a system for declaratively creating graphics, bas..."
##
## text6 :
## "dplyr provides a grammar of data manipulation, providing a c..."
##
## [ reached max_ndoc ... 25 more documents ]8.7.4.1 Summary
## Corpus consisting of 31 documents, showing 10 documents:
##
## Text Types Tokens Sentences
## text1 13 16 1
## text2 19 20 1
## text3 9 9 1
## text4 24 31 2
## text5 37 50 3
## text6 22 29 2
## text7 30 46 3
## text8 40 51 3
## text9 45 57 3
## text10 48 64 38.7.5 Tokens
tokens() segments texts in a corpus into tokens (words or sentences) by word boundaries.
We can remove punctuations or not
8.7.5.1 With punctuations
## Tokens consisting of 31 documents.
## text1 :
## [1] "Install" "all" "the" "packages"
## [5] "in" "the" "tidyverse" "by"
## [9] "running" "install.packages" "(" "\""
## [ ... and 4 more ]
##
## text2 :
## [1] "Run" "library" "(" "tidyverse" ")" "to"
## [7] "load" "the" "core" "tidyverse" "and" "make"
## [ ... and 8 more ]
##
## text3 :
## [1] "Learn" "more"
## [3] "about" "the"
## [5] "tidyverse" "package"
## [7] "at" "https://tidyverse.tidyverse.org"
## [9] "."
##
## text4 :
## [1] "The" "core" "tidyverse" "includes" "the" "packages"
## [7] "that" "you’re" "likely" "to" "use" "in"
## [ ... and 19 more ]
##
## text5 :
## [1] "ggplot2" "is" "a" "system"
## [5] "for" "declaratively" "creating" "graphics"
## [9] "," "based" "on" "The"
## [ ... and 38 more ]
##
## text6 :
## [1] "dplyr" "provides" "a" "grammar" "of"
## [6] "data" "manipulation" "," "providing" "a"
## [11] "consistent" "set"
## [ ... and 17 more ]
##
## [ reached max_ndoc ... 25 more documents ]8.7.5.2 Without punctuations
web_page_txt_corpus_tok_no_punct <- tokens(web_page_txt_corpus, remove_punct = TRUE)
web_page_txt_corpus_tok_no_punct## Tokens consisting of 31 documents.
## text1 :
## [1] "Install" "all" "the" "packages"
## [5] "in" "the" "tidyverse" "by"
## [9] "running" "install.packages" "tidyverse"
##
## text2 :
## [1] "Run" "library" "tidyverse" "to" "load" "the"
## [7] "core" "tidyverse" "and" "make" "it" "available"
## [ ... and 5 more ]
##
## text3 :
## [1] "Learn" "more"
## [3] "about" "the"
## [5] "tidyverse" "package"
## [7] "at" "https://tidyverse.tidyverse.org"
##
## text4 :
## [1] "The" "core" "tidyverse" "includes" "the" "packages"
## [7] "that" "you’re" "likely" "to" "use" "in"
## [ ... and 16 more ]
##
## text5 :
## [1] "ggplot2" "is" "a" "system"
## [5] "for" "declaratively" "creating" "graphics"
## [9] "based" "on" "The" "Grammar"
## [ ... and 29 more ]
##
## text6 :
## [1] "dplyr" "provides" "a" "grammar" "of"
## [6] "data" "manipulation" "providing" "a" "consistent"
## [11] "set" "of"
## [ ... and 12 more ]
##
## [ reached max_ndoc ... 25 more documents ]8.7.6 Stop words
It is best to remove stop words (function/grammatical words) when we use statistical analyses of a corpus.
web_page_txt_corpus_tok_no_punct_no_Stop <- tokens_select(web_page_txt_corpus_tok_no_punct, pattern = stopwords("en", source = "stopwords-iso"), selection = "remove")
web_page_txt_corpus_tok_no_punct_no_Stop## Tokens consisting of 31 documents.
## text1 :
## [1] "Install" "packages" "tidyverse" "running"
## [5] "install.packages" "tidyverse"
##
## text2 :
## [1] "library" "tidyverse" "load" "core" "tidyverse" "current"
## [7] "session"
##
## text3 :
## [1] "Learn" "tidyverse"
## [3] "package" "https://tidyverse.tidyverse.org"
##
## text4 :
## [1] "core" "tidyverse" "includes" "packages" "you’re" "everyday"
## [7] "data" "analyses" "tidyverse" "1.3.0" "packages" "included"
## [ ... and 2 more ]
##
## text5 :
## [1] "ggplot2" "declaratively" "creating" "graphics"
## [5] "based" "Grammar" "Graphics" "provide"
## [9] "data" "ggplot2" "map" "variables"
## [ ... and 7 more ]
##
## text6 :
## [1] "dplyr" "grammar" "data" "manipulation" "providing"
## [6] "consistent" "set" "verbs" "solve" "common"
## [11] "data" "manipulation"
## [ ... and 2 more ]
##
## [ reached max_ndoc ... 25 more documents ]8.7.7 Statistical analyses
We can start by providing statistics (whether descriptives or inferential) based on our corpora.
8.7.7.1 Simple frequency analysis
Here we look at obtaining a simple frequency analysis of usage.
8.7.7.1.1 DFM
We start by generating a DFM (document-feature matrix)
web_page_txt_corpus_tok_no_punct_no_Stop_dfm <- dfm(web_page_txt_corpus_tok_no_punct_no_Stop)
web_page_txt_corpus_tok_no_punct_no_Stop_dfm## Document-feature matrix of: 31 documents, 223 features (95.37% sparse) and 0 docvars.
## features
## docs install packages tidyverse running install.packages library load core
## text1 1 1 2 1 1 0 0 0
## text2 0 0 2 0 0 1 1 1
## text3 0 0 1 0 0 0 0 0
## text4 0 2 3 0 0 0 0 2
## text5 0 0 0 0 0 0 0 0
## text6 0 0 0 0 0 0 0 0
## features
## docs current session
## text1 0 0
## text2 1 1
## text3 0 0
## text4 0 0
## text5 0 0
## text6 0 0
## [ reached max_ndoc ... 25 more documents, reached max_nfeat ... 213 more features ]8.7.7.1.2 Frequencies
web_page_txt_corpus_tok_no_punct_no_Stop_dfm_freq <- textstat_frequency(web_page_txt_corpus_tok_no_punct_no_Stop_dfm)
web_page_txt_corpus_tok_no_punct_no_Stop_dfm_freq## feature frequency rank docfreq group
## 1 tidyverse 15 1 10 all
## 2 data 15 1 10 all
## 3 packages 10 3 8 all
## 4 docs 9 4 9 all
## 5 set 6 5 6 all
## 6 library 4 6 3 all
## 7 core 4 6 3 all
## 8 learn 4 6 4 all
## 9 package 4 6 4 all
## 10 provide 4 6 4 all
## 11 consistent 4 6 4 all
## 12 functions 4 6 4 all
## 13 you’re 3 13 2 all
## 14 variables 3 13 2 all
## 15 dplyr 3 13 3 all
## 16 common 3 13 3 all
## 17 designed 3 13 3 all
## 18 types 3 13 3 all
## 19 purrr 3 13 2 all
## 20 sheets 3 13 2 all
## 21 load 2 21 2 all
## 22 includes 2 21 2 all
## 23 ggplot2 2 21 1 all
## 24 creating 2 21 2 all
## 25 graphics 2 21 1 all
## 26 grammar 2 21 2 all
## 27 manipulation 2 21 1 all
## 28 providing 2 21 2 all
## 29 solve 2 21 2 all
## 30 challenges 2 21 2 all
## 31 tidyr 2 21 2 all
## 32 tidy 2 21 1 all
## 33 variable 2 21 1 all
## 34 column 2 21 1 all
## 35 readr 2 21 2 all
## 36 fast 2 21 2 all
## 37 programming 2 21 2 all
## 38 tools 2 21 2 all
## 39 replace 2 21 2 all
## 40 code 2 21 2 all
## 41 easier 2 21 2 all
## 42 expressive 2 21 2 all
## 43 stringr 2 21 2 all
## 44 strings 2 21 2 all
## 45 forcats 2 21 2 all
## 46 factors 2 21 1 all
## 47 lubridate 2 21 2 all
## 48 specialised 2 21 2 all
## 49 you’ll 2 21 2 all
## 50 reading 2 21 1 all
## 51 files 2 21 2 all
## 52 dbi 2 21 1 all
## 53 maintained 2 21 2 all
## 54 specific 2 21 2 all
## 55 backends 2 21 2 all
## 56 google 2 21 2 all
## 57 addition 2 21 2 all
## 58 > 2 21 1 all
## 59 reprex 2 21 1 all
## 60 install 1 60 1 all
## 61 running 1 60 1 all
## 62 install.packages 1 60 1 all
## 63 current 1 60 1 all
## 64 session 1 60 1 all
## 65 https://tidyverse.tidyverse.org 1 60 1 all
## 66 everyday 1 60 1 all
## 67 analyses 1 60 1 all
## 68 1.3.0 1 60 1 all
## 69 included 1 60 1 all
## 70 declaratively 1 60 1 all
## 71 based 1 60 1 all
## 72 map 1 60 1 all
## 73 aesthetics 1 60 1 all
## 74 graphical 1 60 1 all
## 75 primitives 1 60 1 all
## 76 takes 1 60 1 all
## 77 care 1 60 1 all
## 78 details 1 60 1 all
## 79 verbs 1 60 1 all
## 80 form 1 60 1 all
## 81 friendly 1 60 1 all
## 82 read 1 60 1 all
## 83 rectangular 1 60 1 all
## 84 csv 1 60 1 all
## 85 tsv 1 60 1 all
## 86 fwf 1 60 1 all
## 87 flexibly 1 60 1 all
## 88 parse 1 60 1 all
## 89 wild 1 60 1 all
## 90 cleanly 1 60 1 all
## 91 failing 1 60 1 all
## 92 unexpectedly 1 60 1 all
## 93 enhances 1 60 1 all
## 94 r’s 1 60 1 all
## 95 functional 1 60 1 all
## 96 fp 1 60 1 all
## 97 toolkit 1 60 1 all
## 98 complete 1 60 1 all
## 99 vectors 1 60 1 all
## 100 master 1 60 1 all
## 101 basic 1 60 1 all
## 102 concepts 1 60 1 all
## 103 loops 1 60 1 all
## 104 write 1 60 1 all
## 105 tibble 1 60 1 all
## 106 modern 1 60 1 all
## 107 re-imagining 1 60 1 all
## 108 frame 1 60 1 all
## 109 keeping 1 60 1 all
## 110 time 1 60 1 all
## 111 proven 1 60 1 all
## 112 effective 1 60 1 all
## 113 throwing 1 60 1 all
## 114 tibbles 1 60 1 all
## 115 data.frames 1 60 1 all
## 116 lazy 1 60 1 all
## 117 surly 1 60 1 all
## 118 complain 1 60 1 all
## 119 forcing 1 60 1 all
## 120 confront 1 60 1 all
## 121 earlier 1 60 1 all
## 122 typically 1 60 1 all
## 123 leading 1 60 1 all
## 124 cleaner 1 60 1 all
## 125 cohesive 1 60 1 all
## 126 easy 1 60 1 all
## 127 built 1 60 1 all
## 128 stringi 1 60 1 all
## 129 icu 1 60 1 all
## 130 correct 1 60 1 all
## 131 implementations 1 60 1 all
## 132 string 1 60 1 all
## 133 manipulations 1 60 1 all
## 134 suite 1 60 1 all
## 135 handle 1 60 1 all
## 136 categorical 1 60 1 all
## 137 fixed 1 60 1 all
## 138 values 1 60 1 all
## 139 date-times 1 60 1 all
## 140 extending 1 60 1 all
## 141 improving 1 60 1 all
## 142 r's 1 60 1 all
## 143 existing 1 60 1 all
## 144 support 1 60 1 all
## 145 usage 1 60 1 all
## 146 loaded 1 60 1 all
## 147 automatically 1 60 1 all
## 148 flat 1 60 1 all
## 149 installs 1 60 1 all
## 150 relational 1 60 1 all
## 151 databases 1 60 1 all
## 152 kirill 1 60 1 all
## 153 müller 1 60 1 all
## 154 pair 1 60 1 all
## 155 database 1 60 1 all
## 156 rsqlite 1 60 1 all
## 157 rmariadb 1 60 1 all
## 158 rpostgres 1 60 1 all
## 159 odbc 1 60 1 all
## 160 https://db.rstudio.com 1 60 1 all
## 161 spss 1 60 1 all
## 162 stata 1 60 1 all
## 163 sas 1 60 1 all
## 164 httr 1 60 1 all
## 165 apis 1 60 1 all
## 166 readxl 1 60 1 all
## 167 xls 1 60 1 all
## 168 xlsx 1 60 1 all
## 169 googlesheets4 1 60 1 all
## 170 api 1 60 1 all
## 171 v4 1 60 1 all
## 172 googledrive 1 60 1 all
## 173 drive 1 60 1 all
## 174 rvest 1 60 1 all
## 175 scraping 1 60 1 all
## 176 jsonlite 1 60 1 all
## 177 json 1 60 1 all
## 178 jeroen 1 60 1 all
## 179 ooms 1 60 1 all
## 180 xml2 1 60 1 all
## 181 xml 1 60 1 all
## 182 specialized 1 60 1 all
## 183 interface 1 60 1 all
## 184 syntax 1 60 1 all
## 185 natural 1 60 1 all
## 186 methods 1 60 1 all
## 187 iterating 1 60 1 all
## 188 objects 1 60 1 all
## 189 additional 1 60 1 all
## 190 magrittr 1 60 1 all
## 191 pipe 1 60 1 all
## 192 piping 1 60 1 all
## 193 operators 1 60 1 all
## 194 $ 1 60 1 all
## 195 < 1 60 1 all
## 196 glue 1 60 1 all
## 197 alternative 1 60 1 all
## 198 paste 1 60 1 all
## 199 combine 1 60 1 all
## 200 modeling 1 60 1 all
## 201 collection 1 60 1 all
## 202 tidymodels 1 60 1 all
## 203 modelr 1 60 1 all
## 204 r4ds 1 60 1 all
## 205 comprehensive 1 60 1 all
## 206 foundation 1 60 1 all
## 207 models 1 60 1 all
## 208 visit 1 60 1 all
## 209 started 1 60 1 all
## 210 guide 1 60 1 all
## 211 detailed 1 60 1 all
## 212 examples 1 60 1 all
## 213 straight 1 60 1 all
## 214 reporting 1 60 1 all
## 215 bug 1 60 1 all
## 216 requesting 1 60 1 all
## 217 feature 1 60 1 all
## 218 succeed 1 60 1 all
## 219 include 1 60 1 all
## 220 reproducible 1 60 1 all
## 221 precisely 1 60 1 all
## 222 meant 1 60 1 all
## 223 tips 1 60 1 all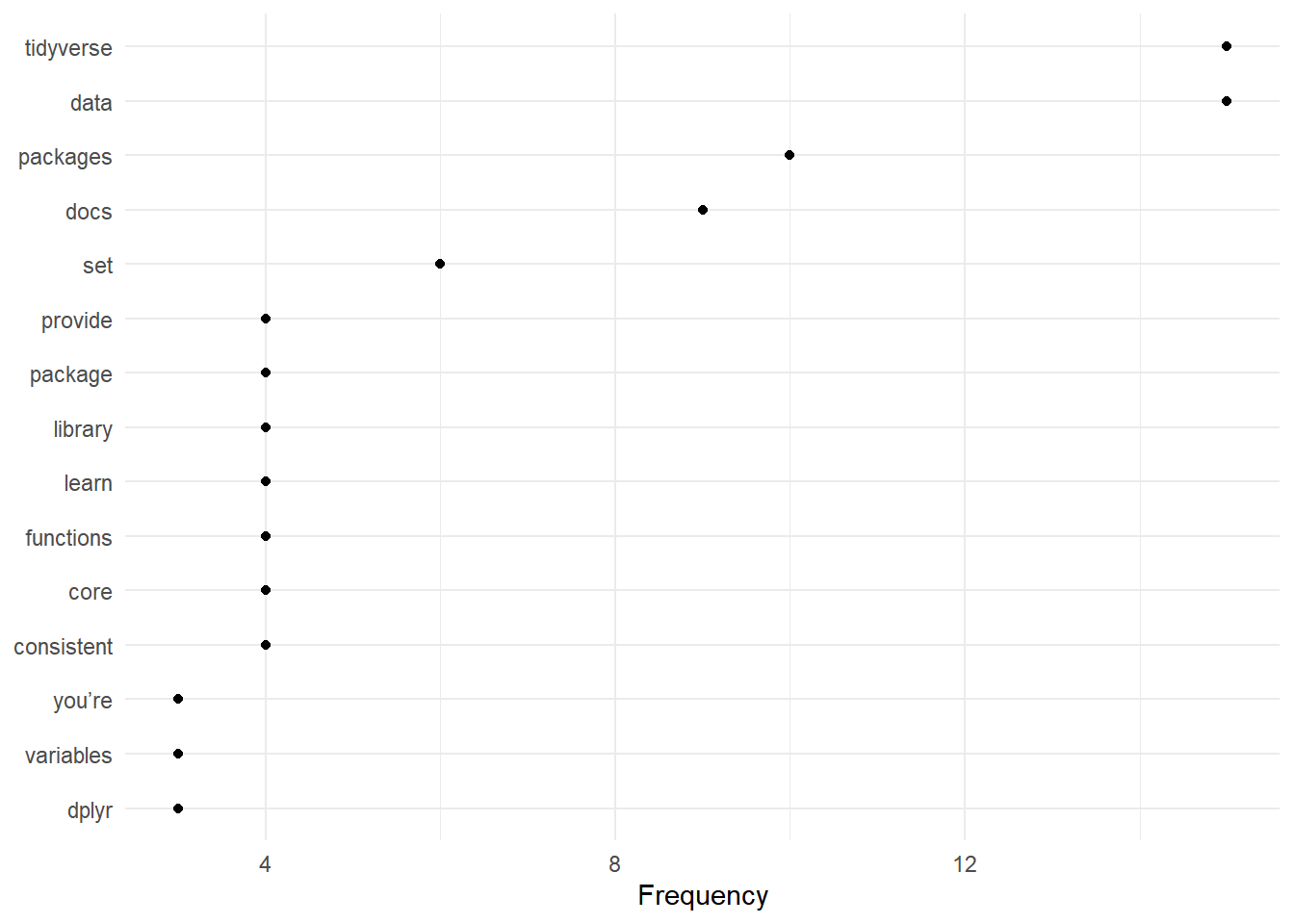
8.7.7.2 Lexical diversity
We can compute the lexical diversity in a document. This is a measure allowing us to provide a statistical account of diversity in the choice of lexical items in a text. See the different measures implemented here
8.7.7.2.1 TTR (Type-Token Ratio)
8.7.7.2.1.1 Computing TTR
web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_ttr <- textstat_lexdiv(web_page_txt_corpus_tok_no_punct_no_Stop_dfm, measure = "TTR")
head(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_ttr, 5)## document TTR
## 1 text1 0.8333333
## 2 text2 0.8571429
## 3 text3 1.0000000
## 4 text4 0.6923077
## 5 text5 0.89473688.7.7.2.1.2 Plotting TTR
plot(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_ttr$TTR, type = "l", xaxt = "n", xlab = NULL, ylab = "TTR")
grid()
axis(1, at = seq_len(nrow(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_ttr)), labels = web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_ttr$document)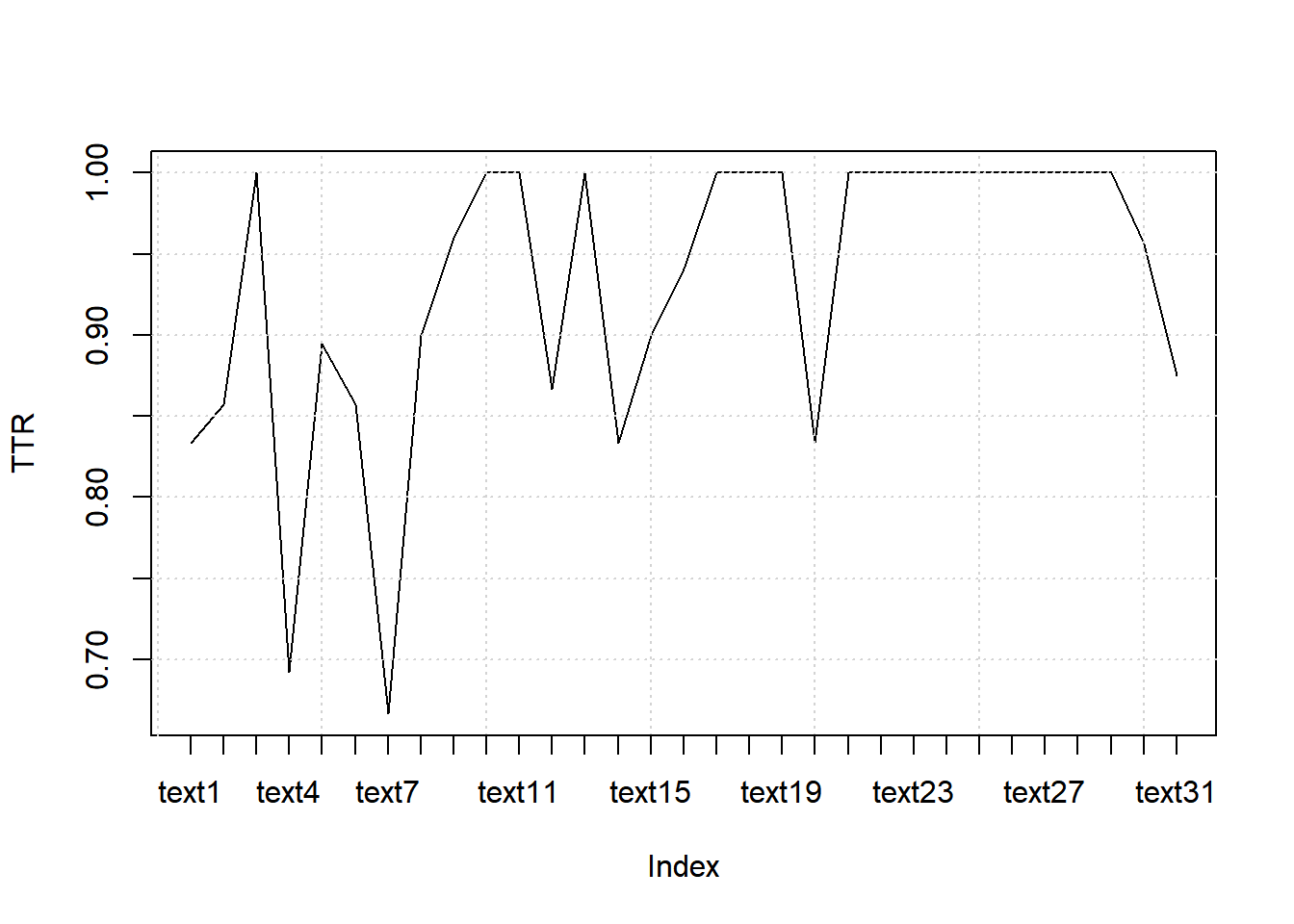
8.7.7.2.2 CTTR (Corrected Type-Token Ratio)
8.7.7.2.2.1 Computing CTTR
web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_cttr <- textstat_lexdiv(web_page_txt_corpus_tok_no_punct_no_Stop_dfm, measure = "CTTR")
head(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_cttr, 5)## document CTTR
## 1 text1 1.443376
## 2 text2 1.603567
## 3 text3 1.224745
## 4 text4 1.765045
## 5 text5 2.7577648.7.7.2.2.2 Plotting TTR
plot(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_cttr$CTTR, type = "l", xaxt = "n", xlab = NULL, ylab = "CTTR")
grid()
axis(1, at = seq_len(nrow(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_cttr)), labels = web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_cttr$document)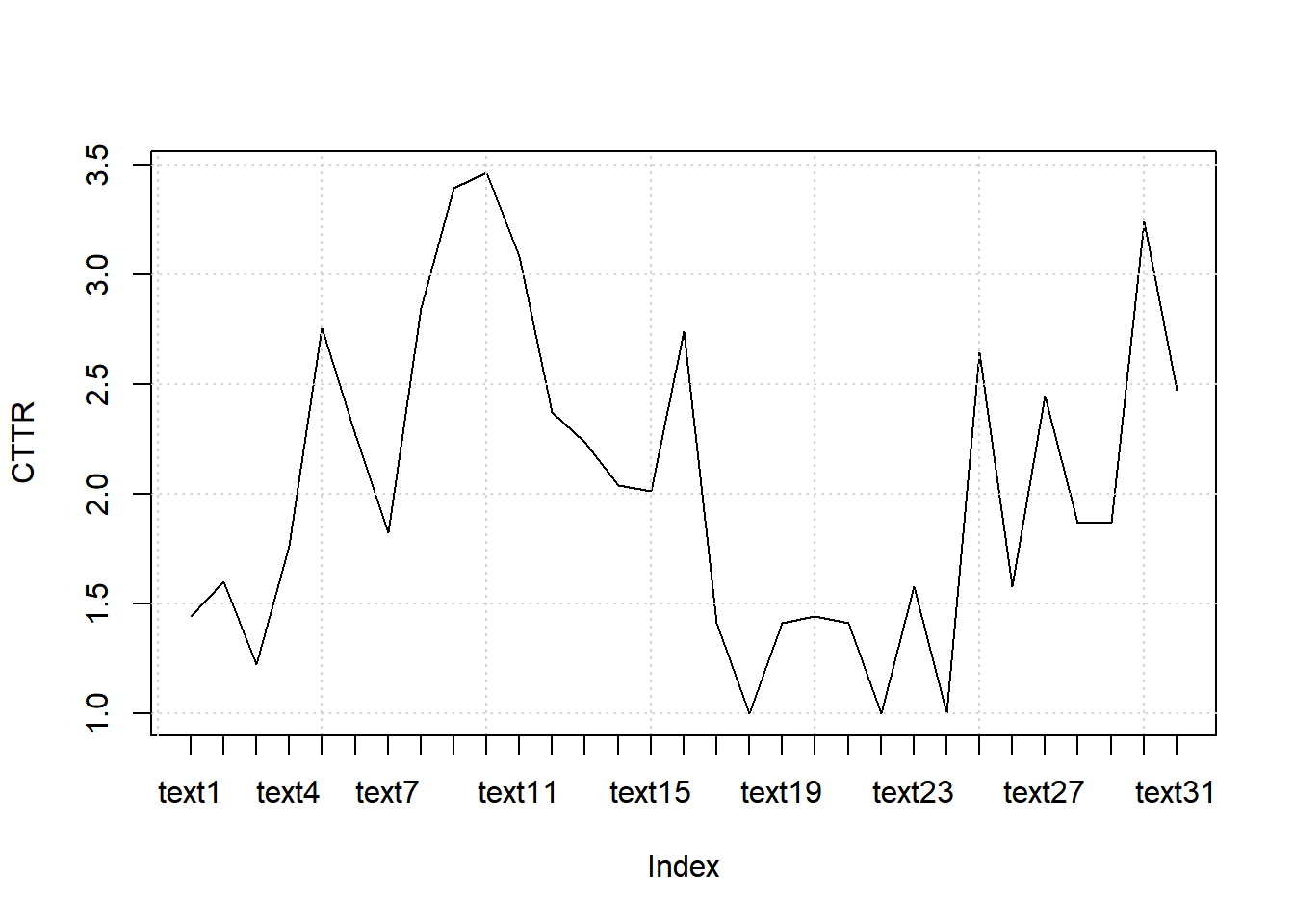
8.7.7.2.3 K (Yule’s K)
8.7.7.2.3.1 Computing K
web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_K <- textstat_lexdiv(web_page_txt_corpus_tok_no_punct_no_Stop_dfm, measure = "K")
head(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_K, 5)## document K
## 1 text1 555.5556
## 2 text2 408.1633
## 3 text3 0.0000
## 4 text4 591.7160
## 5 text5 110.80338.7.7.2.3.2 Plotting K
plot(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_K$K, type = "l", xaxt = "n", xlab = NULL, ylab = expression(italic(K)))
grid()
axis(1, at = seq_len(nrow(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_K)), labels = web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_lexdiv_K$document)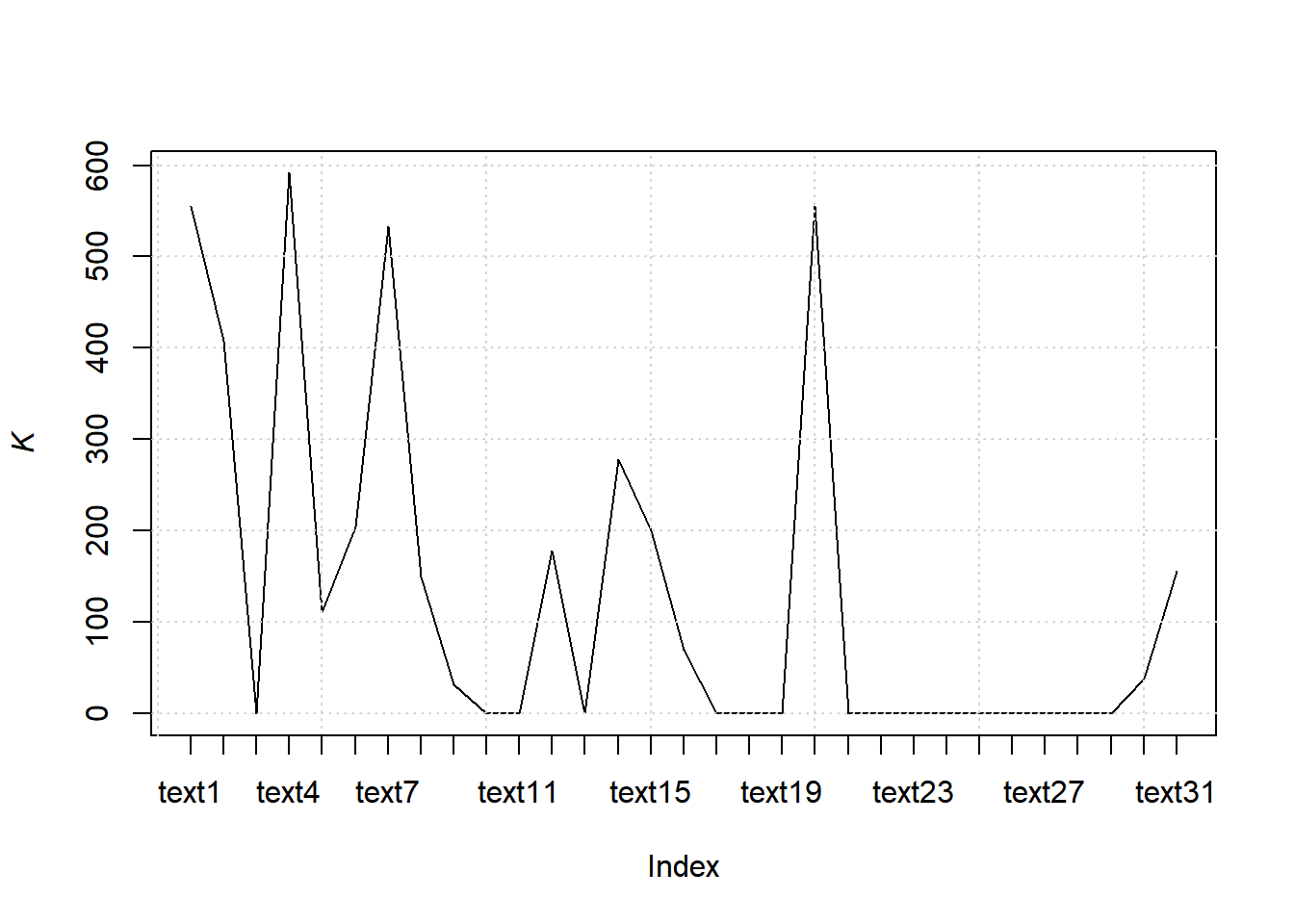
8.7.7.3 Keyness - relative frequency analysis
The relative frequency analysis allows to provide a statistical analysis of frequent words as a function of a target reference level. For this dataset, we do not have a specific target. Hence the comparison is done based on the full dataset.
8.7.7.3.1 Computing keyness
web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_key <- textstat_keyness(web_page_txt_corpus_tok_no_punct_no_Stop_dfm)
head(web_page_txt_corpus_tok_no_punct_no_Stop_dfm_tstat_key, 10)## feature chi2 p n_target n_reference
## 1 install 13.83568364 0.000199511 1 0
## 2 install.packages 13.83568364 0.000199511 1 0
## 3 running 13.83568364 0.000199511 1 0
## 4 tidyverse 6.36092880 0.011666046 2 13
## 5 packages 0.65583008 0.418035953 1 9
## 6 $ -0.01754298 0.894628443 0 1
## 7 1.3.0 -0.01754298 0.894628443 0 1
## 8 < -0.01754298 0.894628443 0 1
## 9 additional -0.01754298 0.894628443 0 1
## 10 aesthetics -0.01754298 0.894628443 0 1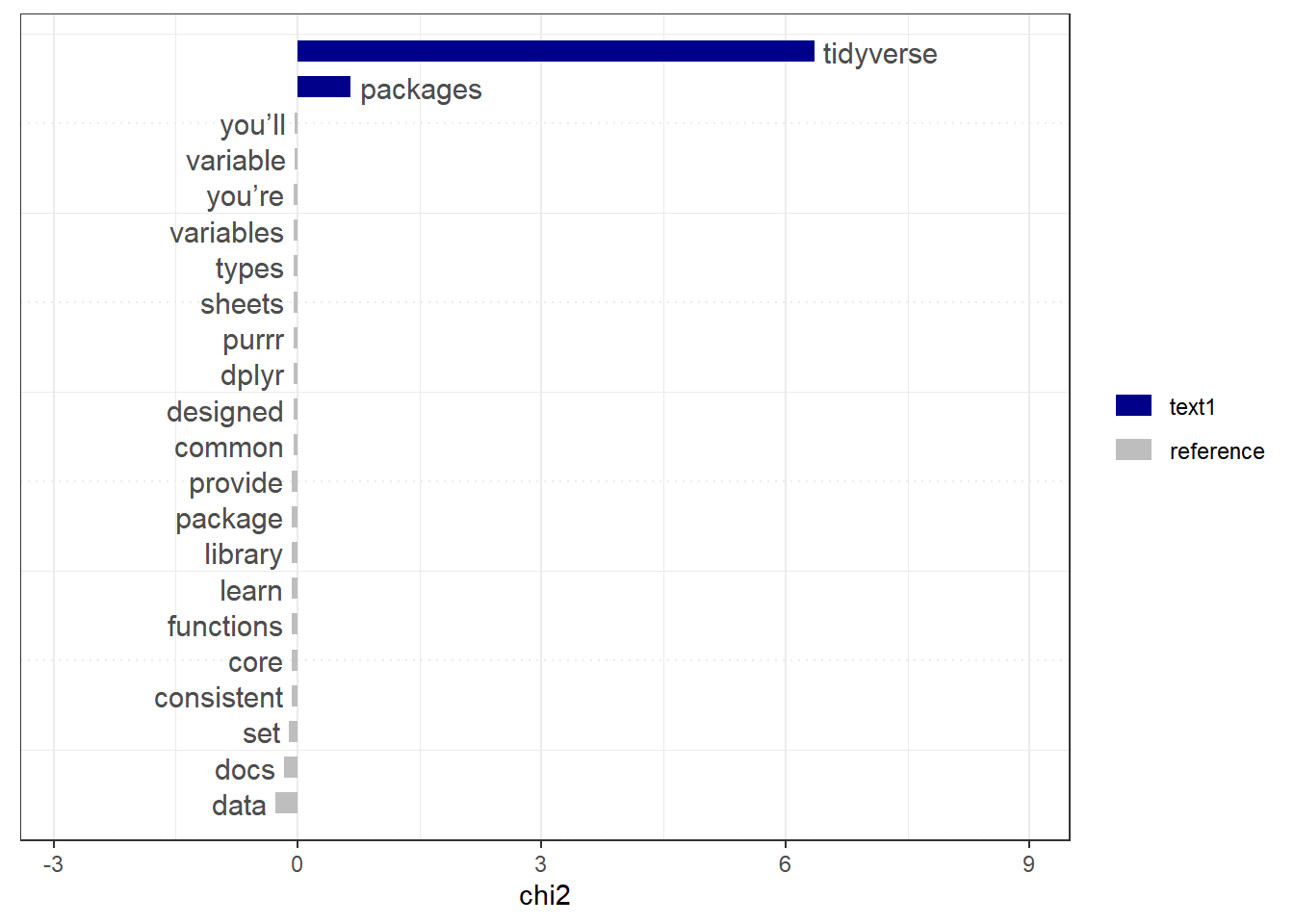
8.7.7.4 Collocations - scoring multi-word expressions
A collocation analysis is a way to identify contiguous collocations of words, i.e., multi-word expressions. Depending on the language, these can be identified based on capitalisation (e.g., proper names) as in English texts. However, this is not the same across languages.
We look for capital letters in our text. The result provides Wald’s Lamda and z statistics. Usually, any z value higher or equal to 2 is statistically significant. To compute p values, we use the probability of a normal distribution based on a mean of 0 and an SD of 1. This is appended to the table.
Here, we do not have any compound words!
web_page_txt_corpus_tok_no_punct_no_Stop_tstat_col_caps <- tokens_select(web_page_txt_corpus_tok_no_punct_no_Stop, pattern = c("^[a-z]", "^[A-Z]"), valuetype = "regex", case_insensitive = FALSE, padding = TRUE) %>% textstat_collocations(min_count = 10) %>% mutate(p_value = 1 - pnorm(z, 0, 1))
web_page_txt_corpus_tok_no_punct_no_Stop_tstat_col_caps## [1] collocation count count_nested length lambda
## [6] z p_value
## <0 rows> (or 0-length row.names)8.7.7.5 Word clouds
We can use word clouds of the top 100 words
set.seed(132)
web_page_txt_corpus_tok_no_punct_no_Stop_dfm %>%
textplot_wordcloud(max_words = 100, color = brewer.pal(8, "Dark2"))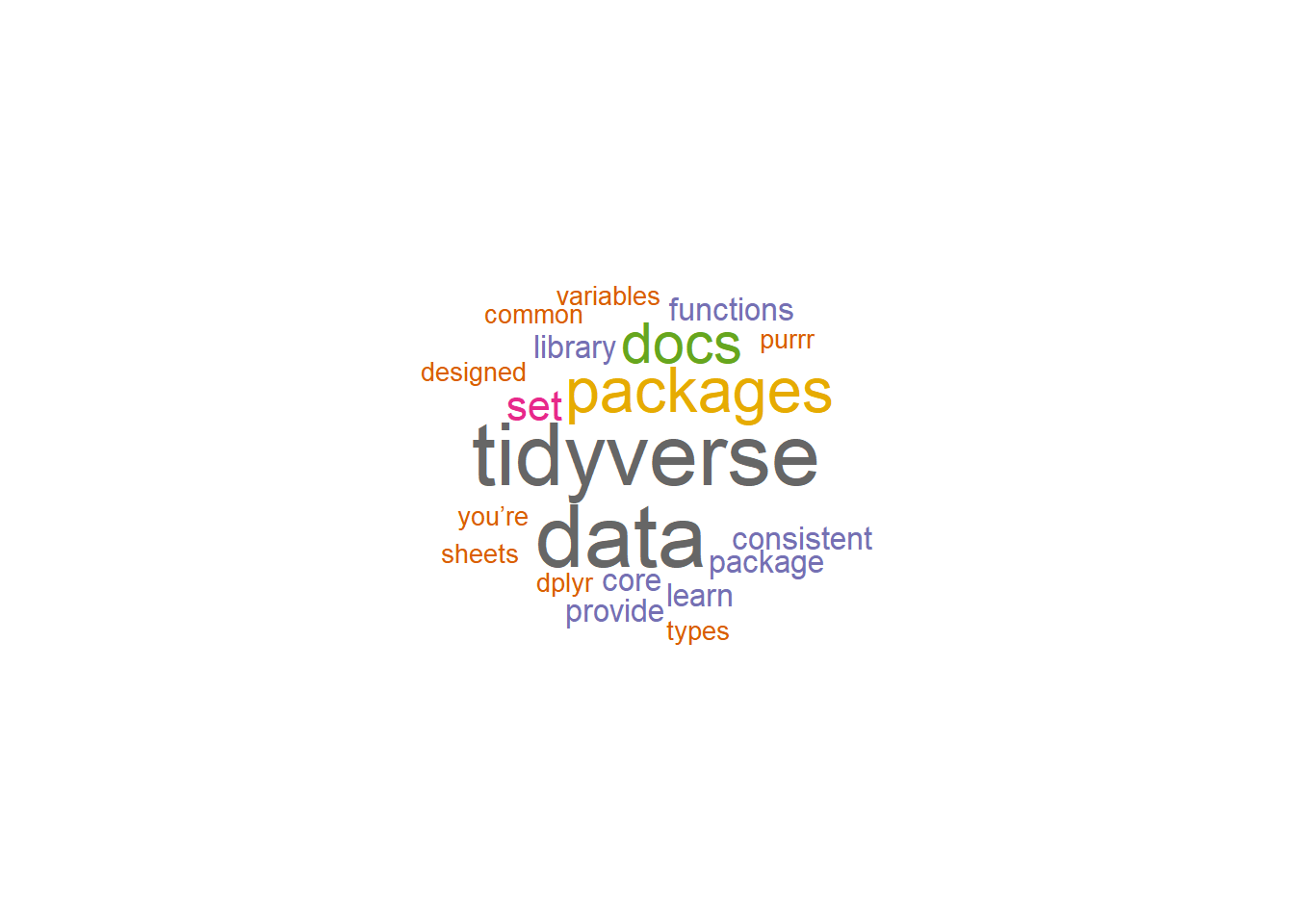
8.7.7.6 Network of feature co-occurrences
A Network of feature co-occurrences allows to obtain association plot of word usage. We use an fcm (feature co-occurrence matrix) based on our DFM.
set.seed(144)
web_page_txt_corpus_tok_no_punct_no_Stop_dfm %>%
dfm_trim(min_termfreq = 3) %>%
textplot_network(min_freq = 0.5)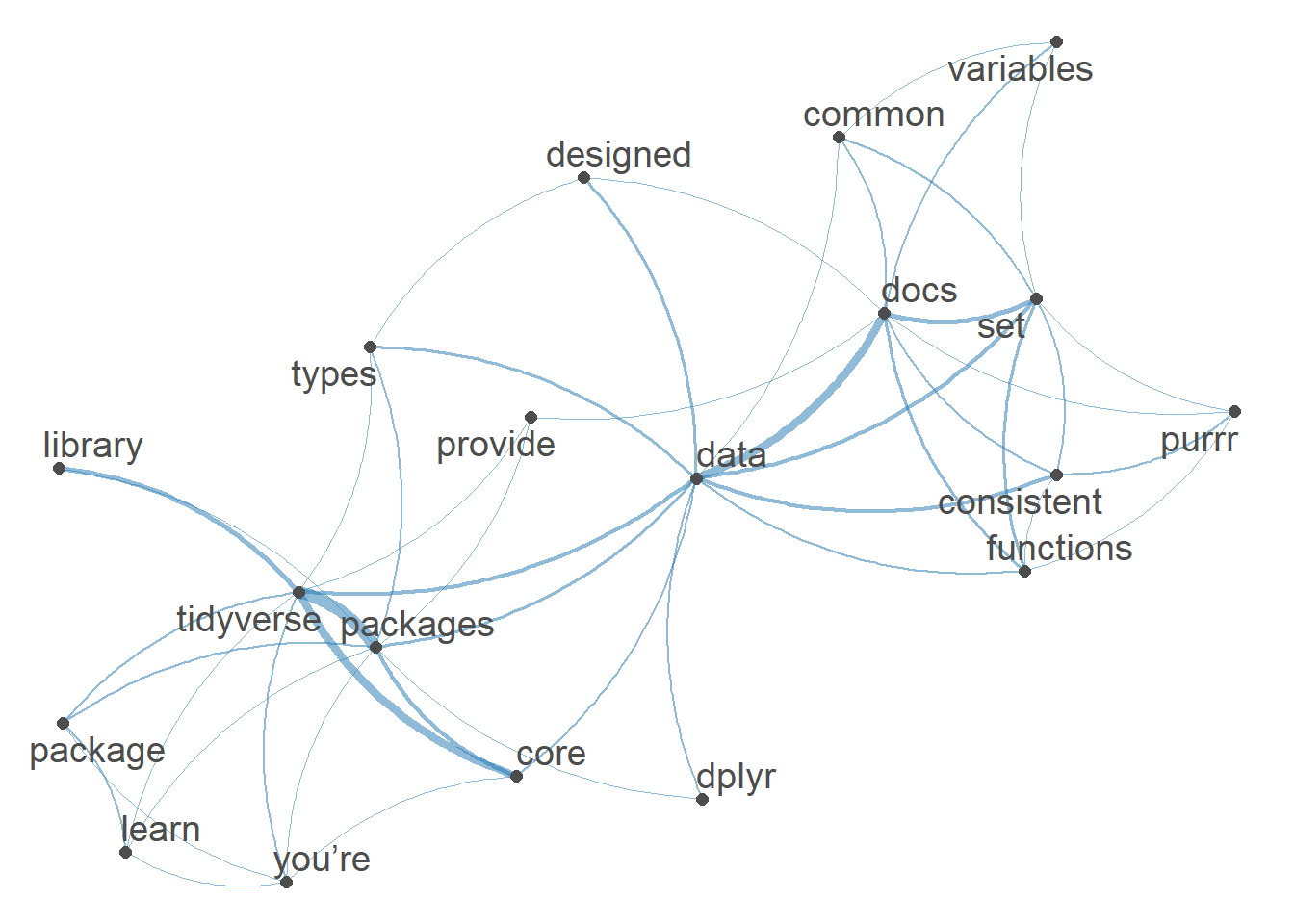
8.7.7.7 Poisson regression
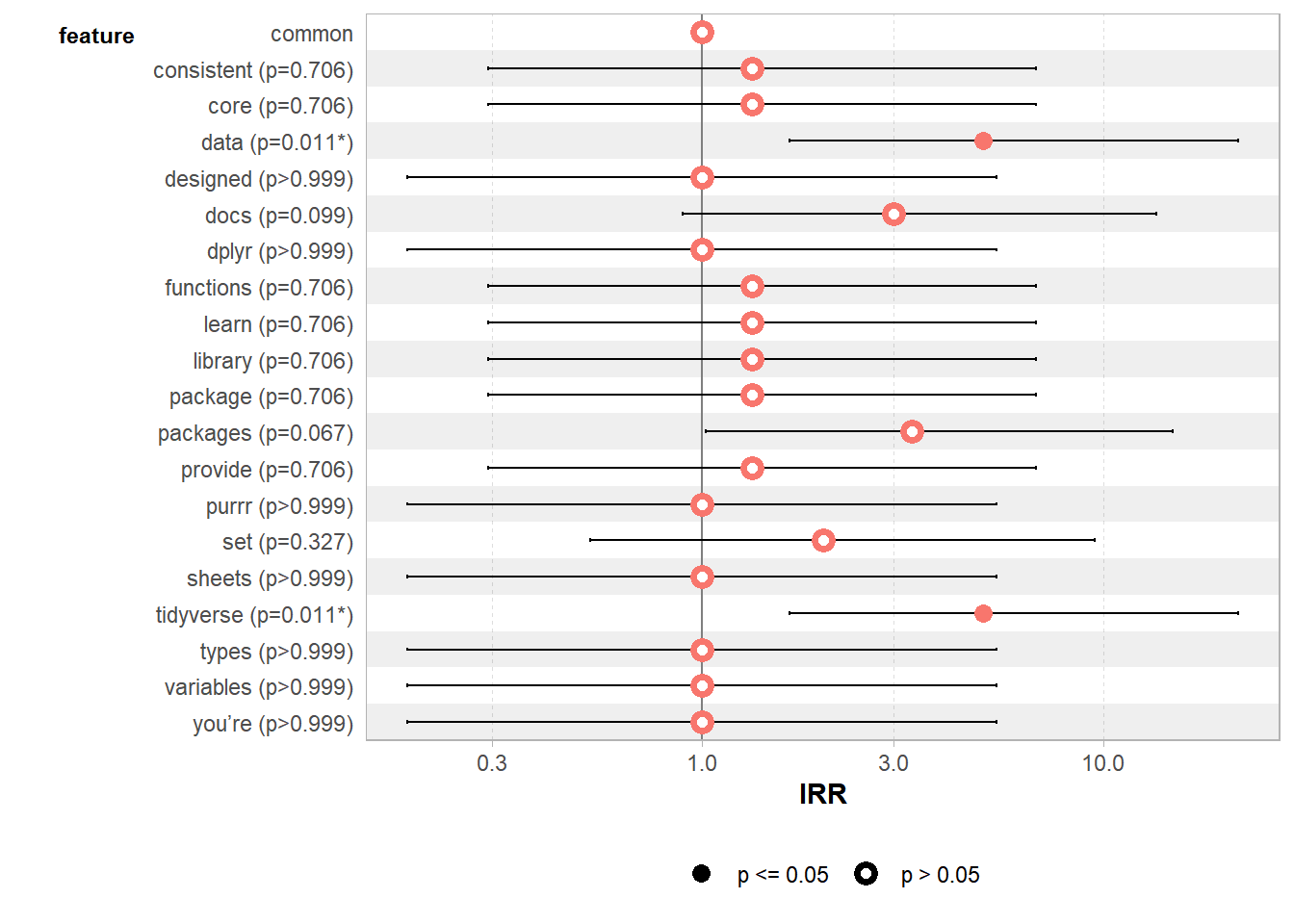
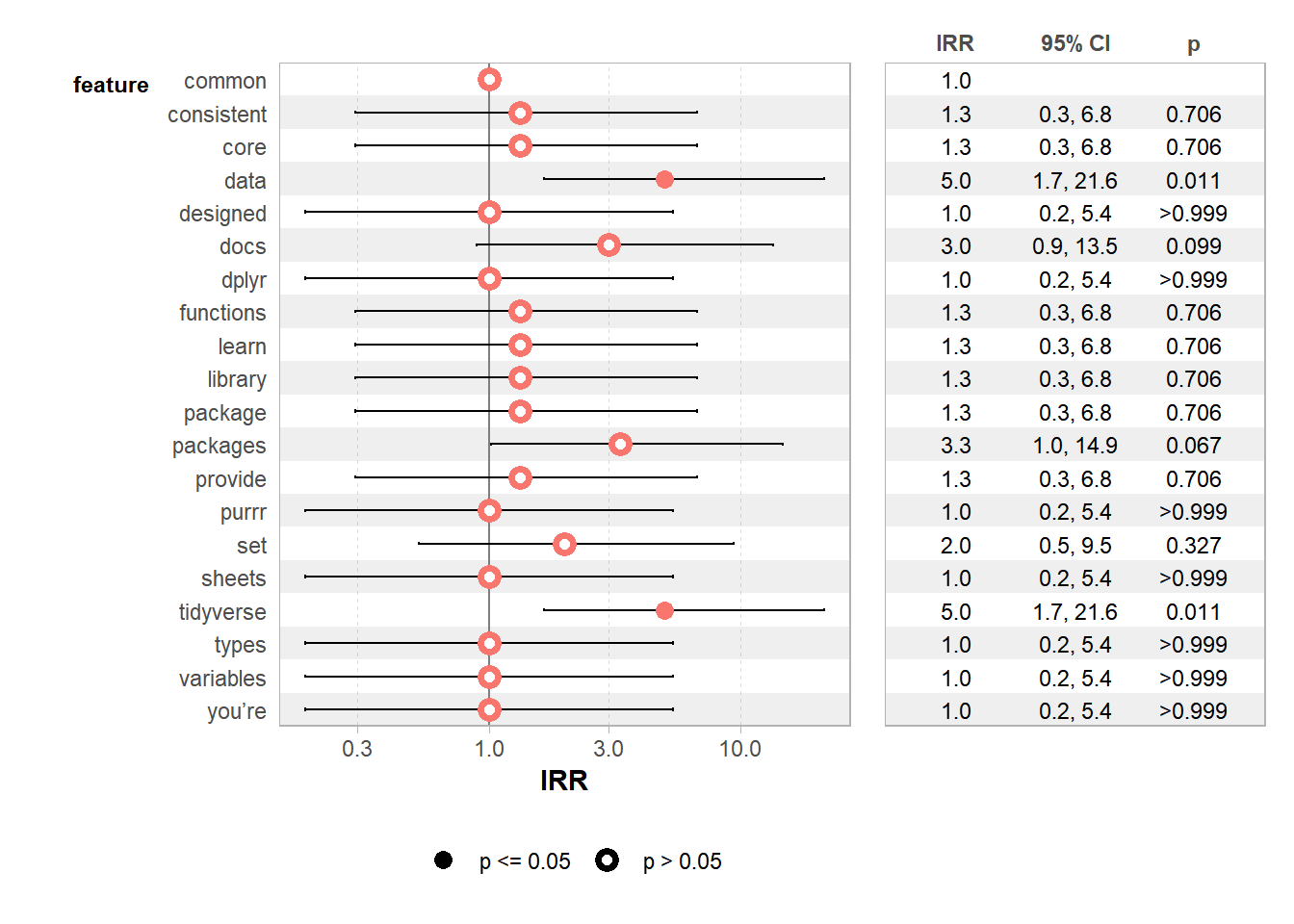
Finally, we run a GLM with a poisson family to evaluate the significance level of our most frequent words.
8.7.7.7.1 Computing GLM
web_page_txt_corpus_GLM <- web_page_txt_corpus_tok_no_punct_no_Stop_dfm_freq %>%
filter(frequency >= 3) %>%
glm(frequency ~ feature, data = ., family = "poisson")
summary(web_page_txt_corpus_GLM)##
## Call:
## glm(formula = frequency ~ feature, family = "poisson", data = .)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.099e+00 5.774e-01 1.903 0.0571 .
## featureconsistent 2.877e-01 7.638e-01 0.377 0.7064
## featurecore 2.877e-01 7.638e-01 0.377 0.7064
## featuredata 1.609e+00 6.325e-01 2.545 0.0109 *
## featuredesigned 3.101e-16 8.165e-01 0.000 1.0000
## featuredocs 1.099e+00 6.667e-01 1.648 0.0994 .
## featuredplyr 1.709e-15 8.165e-01 0.000 1.0000
## featurefunctions 2.877e-01 7.638e-01 0.377 0.7064
## featurelearn 2.877e-01 7.638e-01 0.377 0.7064
## featurelibrary 2.877e-01 7.638e-01 0.377 0.7064
## featurepackage 2.877e-01 7.638e-01 0.377 0.7064
## featurepackages 1.204e+00 6.583e-01 1.829 0.0674 .
## featureprovide 2.877e-01 7.638e-01 0.377 0.7064
## featurepurrr 2.335e-16 8.165e-01 0.000 1.0000
## featureset 6.931e-01 7.071e-01 0.980 0.3270
## featuresheets 2.703e-16 8.165e-01 0.000 1.0000
## featuretidyverse 1.609e+00 6.325e-01 2.545 0.0109 *
## featuretypes -3.389e-16 8.165e-01 0.000 1.0000
## featurevariables -2.476e-16 8.165e-01 0.000 1.0000
## featureyou’re -8.105e-16 8.165e-01 0.000 1.0000
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 4.1053e+01 on 19 degrees of freedom
## Residual deviance: 1.9984e-15 on 0 degrees of freedom
## AIC: 107.78
##
## Number of Fisher Scoring iterations: 3